Quick introduction to generating counterfactual explanations using DiCE
Exploring “what-if” scenarios is an important way to inspect a machine learning (ML) model. The DiCE library helps you to understand an ML model by generating “what-if” data points that lead to the desired model output. Formally, such “what-if” data points are known as counterfactuals, described by the following question: > Given that the model’s output for input \(x\) is \(y\), what would be the output if input \(x\) is changed to \(x'\)?
The answer to the above question can be obtained by simply inputting \(x'\) to the ML model. However, in many cases, we are interested in the reverse question: what changes to \(x\) would lead to a desired change in model’s output? When inspecting a classifier, for instance, we are often interested in knowing the changes to \(x\) that will lead to a desired predicted class. For a regressor, we may be interested in the changes to \(x\) that lead to a desired output range. Ideally, these changes should be proximal to bring out the local decision logic of the classifier, sparse to highlight a limited set of features, and diverse to show the different ways in which the same outcome can be achieved. The DiCE library provides an easy interface to generate such counterfactual examples for any ML model.
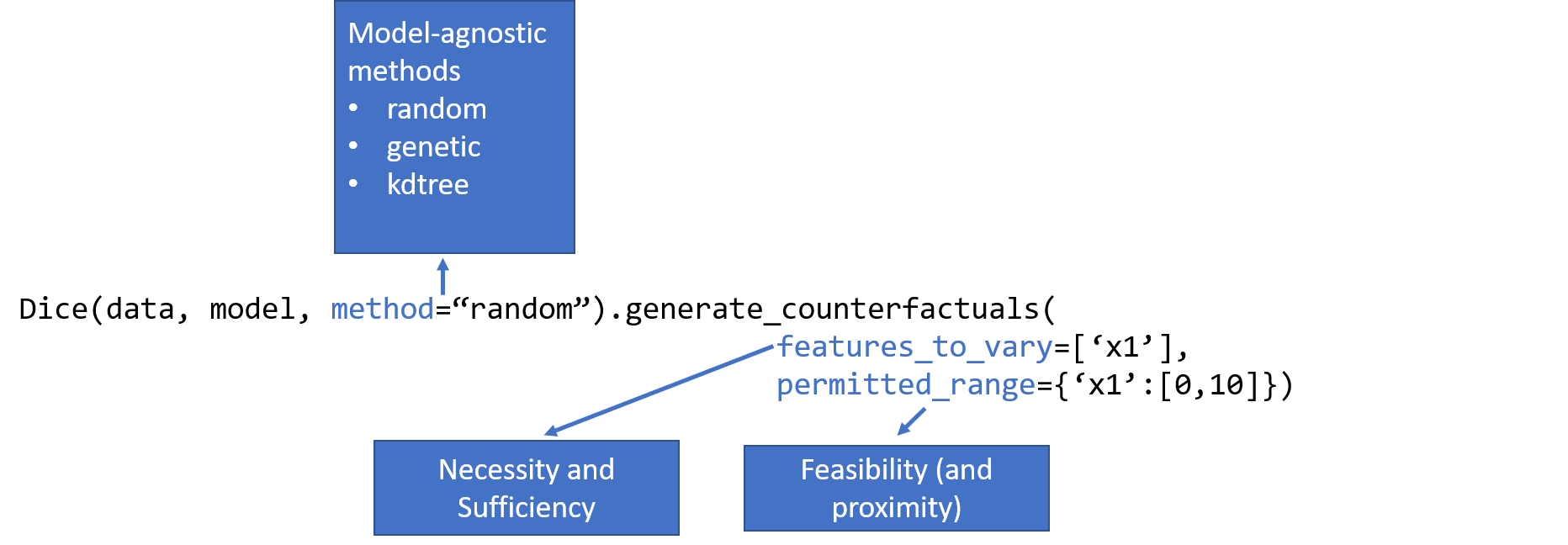
In addition to proximity (minimal changes) and diversity, another important metric for counterfactual examples is their feasibility. If the changes in a counterfactual example are not feasible (e.g., outside the possible range of a particular feature), then the example is less useful. Specifying the possible ranges for continuous features (and possible values for categorical features) is one of the simplest forms of feasibility. DiCE allows you to customize the permitted values for features
through the permitted_range parameter. In general, feasibility is a complex concept based on whether the changes indicated by a counterfactual are feasible for the individual, not just that certain values are feasible (e.g., 20 years may be a feasible value for Age feature, but changing a person’s age from 22 to 20 is not feasible). DiCE will support such constraints in a future release.
Counterfactual examples generated by DiCE are closely related to necessity and sufficiency conditions for causing a given model output. Necessity and sufficiency provide an intuitive way to explain a model’s output. Given an input \(x\) and the model output \(y\), a feature value \(x_i\) is necessary for causing the model output \(y\) if changing \(x_i\) changes the model output, while keeping every other feature constant. Similarly, a feature value \(x_i\) is
sufficient for causing the model output \(y\) if it is impossible to change the model output while keeping \(x_i\) constant. DiCE allows inspecting necessity and sufficiency by setting the features_to_vary parameter. If features_to_vary is set to \(x_i\), then the generated counterfactuals demonstrate the necessity of the feature. If features_to_vary is set to all features except \(x_i\), then the absence of any counterfactuals demonstrates the sufficiency of the
feature. In practice, a single feature may be neither sufficient nor necessary—the formal definitions and the features_to_vary parameter translate easily to sets of features.
Finally, the counterfactuals for an input data point can be used to derive a local importance score for each feature. The local feature importance score ranks features by their frequency of being changed in the generated counterfactuals. Among all the features, necessary features are likely to be changed more often to generate proximal counterfactuals and therefore will receive a higher score. You can use features_to_vary and permitted_range parameteres to refine the search space for
the counterfactuals and consequently, the local importance score. Given a set of input points, the local importance score can be aggregated to provide a global importance score. Compared to explanation methods like LIME or SHAP, feature importance scores generated by DiCE tend to give importance to a larger number of features; more details are in this paper.
To generate counterfactuals, DiCE implements two kinds of methods: model-agnostic and gradient-based.
Model-Agnostic: These methods apply to any black-box classifier or regressor. They are based on sampling nearby points to an input point, while optimizing a loss function based on proximity (and optionally, sparsity, diversity and feasibility). Use this class of methods for sklearn models. Currently supported methods are:
Randomized Search
Genetic Search
KD Tree Search (for counterfactuals from a given training dataset)
Gradient-Based: These methods apply to differentiable models, such as those returned by deep learning libraries like tensorflow and pytorch. They are based on an explicit loss minimization based on proximity, diversity and feasibility. The method is described in this paper.
DiCE requires two inputs: a training dataset and a pre-trained ML model. When the training dataset is unknown (e.g., for privacy reasons), it can also work without access to the full dataset (see this notebook for an example). Below we show a simple example.
[1]:
# Sklearn imports
from sklearn.compose import ColumnTransformer
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder
from sklearn.ensemble import RandomForestClassifier
# DiCE imports
import dice_ml
from dice_ml.utils import helpers # helper functions
[2]:
%load_ext autoreload
%autoreload 2
Preliminaries: Loading a dataset and a ML model trained over it
Loading the Adult dataset
We use the “adult” income dataset from UCI Machine Learning Repository (https://archive.ics.uci.edu/ml/datasets/adult). For demonstration purposes, we transform the data as described in dice_ml.utils.helpers module.
[3]:
dataset = helpers.load_adult_income_dataset()
/mnt/c/Users/amshar/code/dice/dice_ml/utils/helpers.py:79: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
adult_data = adult_data.replace({'income': {'<=50K': 0, '>50K': 1}})
This dataset has 8 features. The outcome is income which is binarized to 0 (low-income, <=50K) or 1 (high-income, >50K).
[4]:
dataset.head()
[4]:
| age | workclass | education | marital_status | occupation | race | gender | hours_per_week | income | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 28 | Private | Bachelors | Single | White-Collar | White | Female | 60 | 0 |
| 1 | 30 | Self-Employed | Assoc | Married | Professional | White | Male | 65 | 1 |
| 2 | 32 | Private | Some-college | Married | White-Collar | White | Male | 50 | 0 |
| 3 | 20 | Private | Some-college | Single | Service | White | Female | 35 | 0 |
| 4 | 41 | Self-Employed | Some-college | Married | White-Collar | White | Male | 50 | 0 |
[5]:
# description of transformed features
adult_info = helpers.get_adult_data_info()
adult_info
[5]:
{'age': 'age',
'workclass': 'type of industry (Government, Other/Unknown, Private, Self-Employed)',
'education': 'education level (Assoc, Bachelors, Doctorate, HS-grad, Masters, Prof-school, School, Some-college)',
'marital_status': 'marital status (Divorced, Married, Separated, Single, Widowed)',
'occupation': 'occupation (Blue-Collar, Other/Unknown, Professional, Sales, Service, White-Collar)',
'race': 'white or other race?',
'gender': 'male or female?',
'hours_per_week': 'total work hours per week',
'income': '0 (<=50K) vs 1 (>50K)'}
Split the dataset into train and test sets.
[6]:
target = dataset["income"]
train_dataset, test_dataset, y_train, y_test = train_test_split(dataset,
target,
test_size=0.2,
random_state=0,
stratify=target)
x_train = train_dataset.drop('income', axis=1)
x_test = test_dataset.drop('income', axis=1)
Given the train dataset, we construct a data object for DiCE. Since continuous and discrete features have different ways of perturbation, we need to specify the names of the continuous features. DiCE also requires the name of the output variable that the ML model will predict.
[7]:
# Step 1: dice_ml.Data
d = dice_ml.Data(dataframe=train_dataset, continuous_features=['age', 'hours_per_week'], outcome_name='income')
Loading the ML model
DiCE supports sklearn, tensorflow and pytorch models.
The variable backend below indicates the implementation type of DiCE we want to use. Four backends are supported: sklearn, TensorFlow 1.x with backend=’TF1’, Tensorflow 2.x with backend=’TF2’, and PyTorch with backend=’PYT’.
Below we show use a trained classification model using sklearn.
[8]:
numerical = ["age", "hours_per_week"]
categorical = x_train.columns.difference(numerical)
categorical_transformer = Pipeline(steps=[
('onehot', OneHotEncoder(handle_unknown='ignore'))])
transformations = ColumnTransformer(
transformers=[
('cat', categorical_transformer, categorical)])
# Append classifier to preprocessing pipeline.
# Now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', transformations),
('classifier', RandomForestClassifier())])
model = clf.fit(x_train, y_train)
Generating counterfactual examples using DiCE
We now initialize the DiCE explainer, which needs a dataset and a model. DiCE provides local explanation for the model m and requires an query input whose outcome needs to be explained.
[9]:
# Using sklearn backend
m = dice_ml.Model(model=model, backend="sklearn")
# Using method=random for generating CFs
exp = dice_ml.Dice(d, m, method="random")
The method parameter specifies the explanation method. DiCE supports three methods for sklearn models: random sampling, genetic algorithm search, and kd-tree based generation.
The next code snippet shows how to generate and visualize counterfactuals. The first argument of the generate_counterfactuals method is the query instances on which counterfactuals are desired. This can be a dataframe with one or more rows.
Below we provide a sample input whose outcome is 0 (low-income) as per the ML model object m. Given the query input, we can now generate counterfactual explanations to show perturbed inputs from the original input where the ML model outputs class 1 (high-income). The last column shows the output of the classifier: income-output >=0.5 is class 1 and income-output<0.5 is class 0.
[10]:
e1 = exp.generate_counterfactuals(x_test[0:1], total_CFs=2, desired_class="opposite")
e1.visualize_as_dataframe(show_only_changes=True)
100%|█████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 2.18it/s]
Query instance (original outcome : 0)
| age | workclass | education | marital_status | occupation | race | gender | hours_per_week | income | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 29 | Private | HS-grad | Married | Blue-Collar | White | Female | 38 | 0 |
Diverse Counterfactual set (new outcome: 1)
| age | workclass | education | marital_status | occupation | race | gender | hours_per_week | income | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | - | Government | - | Single | - | - | - | - | 1 |
| 1 | - | Government | Assoc | - | - | - | - | - | 1 |
The show_only_changes parameter highlights the changes from the query instance. If you would like to see the full feature values for the counterfactuals, set it to False.
[11]:
e1.visualize_as_dataframe(show_only_changes=False)
Query instance (original outcome : 0)
| age | workclass | education | marital_status | occupation | race | gender | hours_per_week | income | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 29 | Private | HS-grad | Married | Blue-Collar | White | Female | 38 | 0 |
Diverse Counterfactual set (new outcome: 1)
| age | workclass | education | marital_status | occupation | race | gender | hours_per_week | income | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 29 | Government | HS-grad | Single | Blue-Collar | White | Female | 38 | 1 |
| 1 | 29 | Government | Assoc | Married | Blue-Collar | White | Female | 38 | 1 |
That’s it! You can try generating counterfactual explanations for other examples using the same code. It is also possible to restrict the features to vary while generating the counterfactuals, and to specify permitted range of features within which the counterfactual should be generated.
[12]:
# Changing only age and education
e2 = exp.generate_counterfactuals(x_test[0:1],
total_CFs=2,
desired_class="opposite",
features_to_vary=["education", "occupation"]
)
e2.visualize_as_dataframe(show_only_changes=True)
100%|█████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 3.02it/s]
Query instance (original outcome : 0)
| age | workclass | education | marital_status | occupation | race | gender | hours_per_week | income | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 29 | Private | HS-grad | Married | Blue-Collar | White | Female | 38 | 0 |
Diverse Counterfactual set (new outcome: 1)
| age | workclass | education | marital_status | occupation | race | gender | hours_per_week | income | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | - | - | Prof-school | - | Professional | - | - | - | 1 |
| 1 | - | - | Masters | - | Sales | - | - | - | 1 |
[13]:
# Restricting age to be between [20,30] and Education to be either {'Doctorate', 'Prof-school'}.
e3 = exp.generate_counterfactuals(x_test[0:1],
total_CFs=2,
desired_class="opposite",
permitted_range={'age': [20, 30], 'education': ['Doctorate', 'Prof-school']})
e3.visualize_as_dataframe(show_only_changes=True)
100%|█████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 3.72it/s]
Query instance (original outcome : 0)
| age | workclass | education | marital_status | occupation | race | gender | hours_per_week | income | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 29 | Private | HS-grad | Married | Blue-Collar | White | Female | 38 | 0 |
Diverse Counterfactual set (new outcome: 1)
| age | workclass | education | marital_status | occupation | race | gender | hours_per_week | income | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | - | Other/Unknown | - | - | Professional | - | - | - | 1 |
| 1 | - | Government | - | Single | - | - | - | - | 1 |
Generating feature attributions (local and global) using DiCE
DiCE can generate feature importance scores using a summary of the counterfactuals generated. Intuitively, a feature that is changed more often when generating proximal counterfactuals for an input is locally important for causing the model’s prediction at the input. Formally, counterfactuals operationalize the necessity criterion for a model explanation: is the feature value necessary for the given model output?
For more details, refer to the paper, Towards Unifying Feature Attribution and Counterfactual Explanations: Different Means to the Same End.
Local feature importance scores
These scores are computed for a given query instance (input point) by summarizing a set of counterfactual examples around the point.
[14]:
query_instance = x_test[0:1]
imp = exp.local_feature_importance(query_instance, total_CFs=10)
print(imp.local_importance)
100%|█████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.65it/s]
[{'workclass': 0.6, 'education': 0.6, 'occupation': 0.5, 'gender': 0.2, 'marital_status': 0.1, 'race': 0.0, 'age': 0.0, 'hours_per_week': 0.0}]
The total_CFs parameter denotes the number of counterfactuals that are used to create the local importance. More the better.
Global feature importance scores
A global importance score per feature can be estimated by aggregating the scores over individual inputs. The more the inputs, the better the estimate for global importance of a feature.
[15]:
query_instances = x_test[0:20]
imp = exp.global_feature_importance(query_instances)
print(imp.summary_importance)
100%|███████████████████████████████████████████████████████████████████████████████████| 20/20 [00:16<00:00, 1.19it/s]
{'education': 0.705, 'occupation': 0.285, 'marital_status': 0.28, 'workclass': 0.23, 'age': 0.2, 'hours_per_week': 0.19, 'race': 0.075, 'gender': 0.075}
Working with deep learning models (TensorFlow and PyTorch)
We now show examples of gradient-based methods with Tensorflow and Pytorch models. Since the gradient-based methods optimize the loss rather than simply sampling some points, they can be slower to generate counterfactuals. The loss is defined by three component: validity (does the CF have the desired model output), proximity (distance of CF from original point should be low), and diversity (multiple CFs should change different features). The DiCE loss formulation is described in the paper, Explaining Machine Learning Classifiers through Diverse Counterfactual Explanations.
Below, we use a pre-trained ML model which produces high accuracy comparable to other baselines. For convenience, we include the sample trained model with the DiCE package.
Explaining a Tensorflow model
[16]:
backend = 'TF2' # needs tensorflow installed
ML_modelpath = helpers.get_adult_income_modelpath(backend=backend)
# Step 2: dice_ml.Model
m = dice_ml.Model(model_path=ML_modelpath, backend=backend, func="ohe-min-max")
2025-07-13 22:26:04.607485: I tensorflow/core/util/port.cc:153] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2025-07-13 22:26:05.168864: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:467] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
E0000 00:00:1752425765.377977 1958 cuda_dnn.cc:8579] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
E0000 00:00:1752425765.438120 1958 cuda_blas.cc:1407] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
W0000 00:00:1752425765.869114 1958 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
W0000 00:00:1752425765.869394 1958 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
W0000 00:00:1752425765.869400 1958 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
W0000 00:00:1752425765.869404 1958 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
2025-07-13 22:26:05.927837: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
We want to note that the time required to find counterfactuals with Tensorflow 2.x’s eager style of execution is significantly greater than that with TensorFlow 1.x’s graph execution.
Based on the data object d and the model object m, we can now instantiate the DiCE class for generating explanations.
[17]:
# Step 3: initiate DiCE
exp = dice_ml.Dice(d, m, method="gradient")
/home/amshar/python-envs/vpy39/lib/python3.9/site-packages/keras/src/layers/core/dense.py:93: UserWarning: Do not pass an `input_shape`/`input_dim` argument to a layer. When using Sequential models, prefer using an `Input(shape)` object as the first layer in the model instead.
super().__init__(activity_regularizer=activity_regularizer, **kwargs)
2025-07-13 22:26:13.425985: E external/local_xla/xla/stream_executor/cuda/cuda_platform.cc:51] failed call to cuInit: INTERNAL: CUDA error: Failed call to cuInit: UNKNOWN ERROR (303)
/home/amshar/python-envs/vpy39/lib/python3.9/site-packages/keras/src/optimizers/base_optimizer.py:86: UserWarning: Argument `decay` is no longer supported and will be ignored.
warnings.warn(
WARNING:absl:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model.
WARNING:absl:Error in loading the saved optimizer state. As a result, your model is starting with a freshly initialized optimizer.
Below we provide query instances from x_test.
[18]:
# generate counterfactuals
dice_exp = exp.generate_counterfactuals(x_test[1:2], total_CFs=4, desired_class="opposite")
# visualize the result, highlight only the changes
dice_exp.visualize_as_dataframe(show_only_changes=True)
100%|█████████████████████████████████████████████████████████████████████████████████████| 1/1 [01:33<00:00, 93.76s/it]
Diverse Counterfactuals found! total time taken: 01 min 33 sec
Query instance (original outcome : 0.6710000038146973)
| age | workclass | education | marital_status | occupation | race | gender | hours_per_week | income | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 50 | Other/Unknown | Some-college | Married | Other/Unknown | White | Male | 40 | 0.671 |
Diverse Counterfactual set (new outcome: 0.0)
| age | workclass | education | marital_status | occupation | race | gender | hours_per_week | income | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 23 | - | - | - | - | - | - | 13 | 0 |
| 1 | 17 | - | - | - | - | Other | - | - | 0 |
| 2 | - | - | School | Single | - | - | - | - | 0 |
| 3 | 62 | - | - | Divorced | Blue-Collar | - | - | - | 0 |
The counterfactuals generated above are slightly different from those shown in our paper, where the loss convergence condition was made more conservative for rigorous experimentation. To replicate the results in the paper, add an argument loss_converge_maxiter=2 (the default value is 1) in the exp.generate_counterfactuals() method above. For more info, see generate_counterfactuals() method in dice_ml.dice_interfaces.dice_tensorflow.py.
Explaining a Pytorch model
Just change the backend variable to ‘PYT’ to use DiCE with PyTorch. Below, we use a pre-trained ML model in PyTorch which produces high accuracy comparable to other baselines. For convenience, we include the sample trained model with the DiCE package. Additionally, we need to provide a data transformer function that converts input dataframe into one-hot encoded/numeric format.
[19]:
backend = 'PYT' # needs pytorch installed
ML_modelpath = helpers.get_adult_income_modelpath(backend=backend)
m = dice_ml.Model(model_path=ML_modelpath, backend=backend, func="ohe-min-max")
Instantiate the DiCE class with the new PyTorch model object m.
[20]:
exp = dice_ml.Dice(d, m, method="gradient")
[21]:
# generate counterfactuals
dice_exp = exp.generate_counterfactuals(x_test[1:3], total_CFs=4, desired_class="opposite")
# highlight only the changes
dice_exp.visualize_as_dataframe(show_only_changes=True)
50%|██████████████████████████████████████████▌ | 1/2 [00:09<00:09, 9.69s/it]
Diverse Counterfactuals found! total time taken: 00 min 09 sec
100%|█████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:17<00:00, 8.58s/it]
Diverse Counterfactuals found! total time taken: 00 min 07 sec
Query instance (original outcome : 0.6179999709129333)
| age | workclass | education | marital_status | occupation | race | gender | hours_per_week | income | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 50 | Other/Unknown | Some-college | Married | Other/Unknown | White | Male | 40 | 0.618 |
Diverse Counterfactual set (new outcome: 0.0)
| age | workclass | education | marital_status | occupation | race | gender | hours_per_week | income | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 38 | - | - | - | - | - | - | 26 | 0 |
| 1 | - | - | - | - | Blue-Collar | - | Female | - | 0 |
| 2 | - | Government | School | Single | - | - | - | - | 0 |
| 3 | 70 | - | - | Divorced | - | Other | - | - | 0 |
Query instance (original outcome : 0.9679999947547913)
| age | workclass | education | marital_status | occupation | race | gender | hours_per_week | income | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 50 | Private | Bachelors | Married | Professional | White | Male | 40 | 0.968 |
Diverse Counterfactual set (new outcome: 0.0)
| age | workclass | education | marital_status | occupation | race | gender | hours_per_week | income | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 18 | - | - | - | - | - | - | 35 | 0 |
| 1 | - | - | Some-college | Separated | Service | - | - | - | 0 |
| 2 | 69 | - | - | Single | - | - | - | - | 0 |
| 3 | - | Other/Unknown | School | - | - | - | Female | - | 0 |
We can also use method-agnostic explainers like “random” or “genetic”.
[22]:
m = dice_ml.Model(model_path=ML_modelpath, backend=backend, func="ohe-min-max")
exp = dice_ml.Dice(d, m, method="random")
[23]:
# generate counterfactuals
dice_exp = exp.generate_counterfactuals(x_test[1:3], total_CFs=4, desired_class="opposite")
# highlight only the changes
dice_exp.visualize_as_dataframe(show_only_changes=True)
100%|█████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 3.52it/s]
Query instance (original outcome : 1)
| age | workclass | education | marital_status | occupation | race | gender | hours_per_week | income | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 50 | Other/Unknown | Some-college | Married | Other/Unknown | White | Male | 40 | 1 |
Diverse Counterfactual set (new outcome: 0)
| age | workclass | education | marital_status | occupation | race | gender | hours_per_week | income | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | - | - | - | Widowed | - | - | - | 78 | 0 |
| 1 | 35 | - | - | - | - | - | - | - | 0 |
| 2 | - | - | HS-grad | - | - | - | - | 45 | 0 |
| 3 | 33 | - | - | - | - | - | - | - | 0 |
Query instance (original outcome : 1)
| age | workclass | education | marital_status | occupation | race | gender | hours_per_week | income | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 50 | Private | Bachelors | Married | Professional | White | Male | 40 | 1 |
Diverse Counterfactual set (new outcome: 0)
| age | workclass | education | marital_status | occupation | race | gender | hours_per_week | income | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | - | - | - | Separated | Sales | - | - | - | 0 |
| 1 | - | Government | - | Widowed | - | - | - | - | 0 |
| 2 | - | - | - | Separated | - | - | - | - | 0 |
| 3 | - | - | School | Single | - | - | - | - | 0 |
More resources: What’s next?
DiCE has multiple configurable options and support for different kinds of models. Follow these notebooks to learn more.
You can constrain the features to vary, weigh the relative importance of different features for computing distance, or specify permitted ranges for each feature. Check out the Customizing Counterfactuals Notebook.
You can use it for multi-class classification or regression models. Counterfactuals for Multi-class Classification and Regression Models Notebook.
Explore the different model-agnostic explanation methods in DiCE. Model-agnostic Counterfactual Generation Methods.
You can generate CFs even without access to training data (e.g., for privacy-sensitive data). DiCE with Private Data Notebook.
Feasibility of counterfactuals is an important consideration. You can try out this VAE-based method that adds a CF likelihood term to the loss. VAE-based Counterfactuals (Pytorch only).